2026年4月8日,特斯拉正式在美国市场分批推送FSD V14.3版本OTA更新。这并非一次常规的小版本迭代。
在马斯克的语境中,FSD一直缺一块“最后的拼图”——用AI神经网络彻底取代控制车辆的最后30万行C++代码。V14.3,正是冲着这块拼图来的。
相比V14.2,此次更新实现了体验功能与底层技术的双层五大跨代升级。马斯克称其为“通往完全无人驾驶的最后一块重要拼图”,英伟达科学家Jim Fan实测后评价:V14.3已通过“物理图灵测试”。
但这块拼图真的补上了吗?
▍那块“拼图”到底是什么?
在判断特斯拉 FSD V14.3 是否取得成功之前,我们首先需要明确,马斯克所说的 “最后一块拼图” 究竟指代什么。
简单来说,它并非硬件升级,而是一次彻底的软件范式革新。
在 V14.2 及更早版本中,即便 FSD 的感知与规划模块已大量采用神经网络技术,最核心的车辆底层控制 —— 包括转向角度、油门与刹车力度调节,依然依赖工程师手写的 30 余万行 C++ 代码。这也直接导致车辆行驶表现生硬,比如黄灯时突兀急刹、遇到停车标识反复制动,同时也无法通过人工编码覆盖所有极端场景。
而马斯克所说的 “最后一块拼图”,正是用 AI 神经网络全面替代这 30 余万行控制代码。让车辆像人类驾驶员一样,通过海量数据学习自主操控车辆,而非机械执行预设的 “条件判断” 指令。
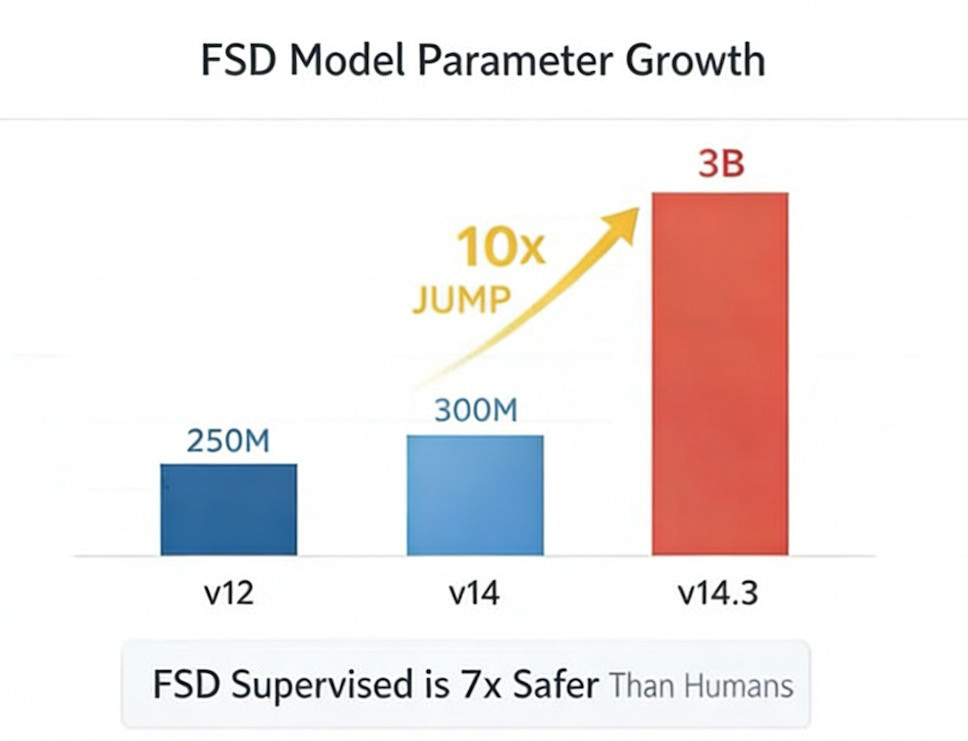
特斯拉 V14.3,也是自 V12 版本转向端到端神经网络架构以来,规模最大的一次底层架构革新。
V11 到 V12 的升级之所以具备革命性,核心在于特斯拉彻底抛弃手工规则编码,全面转向端到端神经网络。而从 V12 到 V14 的迭代,虽让车道选择更合理、驾驶体验更平顺、人工接管次数大幅减少,但模型底层规模并未发生本质变化。
V14.3 则是一次量级上的跃升:模型参数提升 10 倍,意味着它能够承载更丰富的世界信息 —— 更多样的路口类型、更复杂的行人行为、更多施工与天气场景,以及前代模型因容量限制无法学习的大量边缘案例。
让 V14.3 真正成为 “最后一块拼图” 的关键,在于其具备了推理能力。放在自动驾驶场景中,推理即车辆可以像人类一样提前预判、主动思考。它是连接监督式与无监督 FSD 的关键桥梁:没有推理能力,车辆只是高效的驾驶辅助,面对模糊场景仍需人类介入;拥有推理能力,车辆便可自主应对复杂未知状况。这也正是马斯克将其定义为最后一块拼图的核心原因。
V14.3的解决方案,远比外界预想的要激进。它没有依赖新硬件,而是在软件底层动了一场大手术。
第一刀,切在了编译器上。特斯拉基于MLIR框架,从零重写了AI编译器与运行环境。MLIR框架的创造者Chris Lattner曾评价说,这可能是“Robotaxi一直期待的关键突破”。结果是:车辆的反应时间缩短了20%。 别小看这20%,在时速80公里的紧急避险中,这意味着一米多的刹车距离,生死之差。
第二刀,切在了架构上。V14.3彻底抛弃了“感知-规划-控制”三段式模块化设计,切换为“全域一段式纯端到端”。摄像头的原始像素信号,可以直接输出转向、刹车、油门指令。中间环节的误差被消灭,车辆第一次拥有了流畅的“直觉”。
第三刀,植入了“记忆与预判”。V14.3的神经网络参数量提升了十倍,并具备了3-5秒的时空记忆能力。它不再是一个“健忘”的AI,它能记住前几秒谁突然切入了车道,并基于此推演未来3-5秒的人车轨迹。正如英伟达科学家Jim Fan实测后的评价:V14.3已经通过了“物理图灵测试”——你很难分辨这到底是神经网络还是人类在开车。
▍三大核心进化:更果断、更聪明、更少接管
基于底层编译器的提升,对比V14.2,V14.3在驾驶行为、长尾场景和系统稳定性三个层面带来了可感知的进化:
1. 驾驶行为更果断
泊车:地图上会清晰显示车辆选定的目标车位(P图标),泊车操作从犹豫不决变得“一把入库”。
黄灯与停止标志:解决了V14.2版本中频繁“急刹刺探”的顽疾,车辆现在能根据路况和车速,更自信地选择是果断通过黄灯还是平稳停下。
2. 长尾场景应对更聪明
特殊车辆:增强了对救护车、消防车、校车等紧急车辆的识别和避让逻辑。
道路异物:通过分析车队数据,优化了对路面侵入物(如轮胎、树枝、纸箱)的应对能力。
小动物避让:在强化学习训练中增加了主动安全的奖励机制,提升了避让小型动物的能力。
3. 系统稳定性和驾驶员监控提升
自动恢复:改进了对临时系统降级(如摄像头或算力波动)的处理,车辆能在无需驾驶员干预的情况下维持控制并自动恢复,减少了不必要的人工接管。
一位北美首批用户在85英里的长途实测中,实现了全程零干预。他评价道:“暴雨高速上的稳定性提升巨大,日常通勤的疲劳感显著下降。”
有行业媒体评测:新版驾驶流畅度大幅提升,拥堵跟车顿挫减少 82%,无保护左转成功率升至 98%;但纯视觉固有短板仍存,强光、雨雾天气,以及窄路、低矮障碍物识别表现,依旧不及华为 ADS 系列激光融合方案。
▍即将推出:V14.3的“未完待续”
需要指出的是,V14.3并非“完全体”。根据特斯拉官方更新说明,以下三项关键改进被列为“即将推出”,尚未包含在当前版本中:
1. 将推理能力扩展至目的地处理之外的所有行为
当前版本的推理能力主要集中在目的地路径规划上。即将到来的更新将把这种“理解场景语义”的能力扩展到所有驾驶行为中——包括变道、超车、让行、通过复杂路口等。这意味着车辆将从“知道要去哪”升级为“理解为什么要这么开”。
2. 增加避让坑洼路面功能
这是用户呼声极高的功能之一。坑洼、井盖下沉、路面破损等路况,在V14.2及当前V14.3版本中处理得并不完美。即将上线的坑洼避让功能,将让车辆能够主动识别并规避路面缺陷,既保护轮胎和悬挂,也提升乘坐舒适性。
3. 提升驾驶员监测系统的灵敏度
当前的DMS在某些场景下仍存在识别盲区。即将到来的升级将带来三方面改进:
眼球追踪精度提升:更准确地判断驾驶员视线方向,区分“看路”和“分心”
眼镜佩戴处理优化:解决戴墨镜、近视镜时红外摄像头无法准确捕捉眼动的问题
多变光照条件下的更高准确度:逆光、夜间、隧道出入等光照剧烈变化的场景下,DMS仍能稳定工作
这三项功能的补齐,将让V14.3从一个“强大的驾驶AI”进化成一个“更安全、更全面、更懂路况”的系统——尤其是坑洼避让和DMS优化,对于道路质量参差不齐、驾驶环境复杂的场景而言,其重要性不亚于端到端架构本身。
▍拼图补上了吗?——我们离无人驾驶还有多远
答案是:关键的一块拼上了,但并非全部。
从技术范式看,是的。V14.3通过重写编译器、端到端架构和时空记忆,彻底解决了“车辆操控机械化”的顽疾。20%的反应时间提升、98%的无保护左转成功率、零干预的长途表现,证明纯视觉路线在“驾驶智商”上已经跨越了奇点。马斯克所说的“安全水平可达人类2-3倍”,在大量常规场景下已不再是空话。
但从终极无人驾驶(L4级Robotaxi)看,仍有缺口。
缺口一:纯视觉的物理天花板尚存。尽管V14.3大幅强化了低能见度能力,但行业评测媒体指出:在强光眩目、浓雾、以及识别低矮障碍物(如路面散落的纸箱、轮胎)时,FSD的表现仍不及华为ADS系列的激光雷达融合方案。 摄像头毕竟是被动光传感器,在极端天气下的可靠性依然是个问号。
缺口二:停车场与窄路场景仍需打磨。首批用户反馈,V14.3在部分停车场仍有泊车歪斜、路径绕路现象;在人车混行的窄路上,行驶风格偏保守,容易被非机动车“欺负”。这些场景的完美解决,需要更海量的本土化数据训练。
缺口三:HW3.0老车主的尴尬。V14.3仅支持HW4.0车型,HW3.0只能等到2026年Q2末推送“精简Lite版”。这意味着数百万存量特斯拉车辆,无法享受这次“换脑”红利。无人驾驶的普及,受制于硬件代差。
▍结语:终局对决刚刚开始
FSD V14.3的推送,标志着特斯拉纯视觉路线完成了一次里程碑式的进化。它补上了“AI直接操控车辆”的最后一块技术拼图,让FSD从一个“辅助驾驶工具”,真正迈向了“具备驾驶智慧的AI司机”。
然而,补上拼图不等于完成了整幅画卷。纯视觉路线的终极可靠性、复杂本土场景的适配能力、以及硬件迭代带来的用户分化,都是特斯拉在通往Robotaxi道路上必须翻越的山丘。
当前,全球智驾行业已形成两大路线的终局对决:特斯拉的纯视觉vs华为的激光雷达融合。两条路线各有优劣,没有哪一条是绝对的“正确答案”。特斯拉的优势在于全球数据飞轮和极致的成本控制;华为的优势在于传感器冗余带来的安全边界,以及对中国复杂路况的深度适配。
至于FSD何时能登陆中国、并且像一位中国老司机那样开车——相信这一刻很快就会来到。但届时,它要挑战的,是一个已经跑在前面很远的对手。这场终局对决,才刚刚开始。
来源:第一电动网
作者:李艳娇







